python爬取琳琅社区整站视频操作教程
该项目用于爬取琳琅社区整站视频(仅供学习)
主要使用:python3.7 + scrapy2.19 + Mysql 8.0 + win10
首先确定需要爬取的内容,定义item:

然后编写爬虫文件:构造初始url的解析函数,得到琳琅网站的视频分类请求,并在本地生成存储的主目录

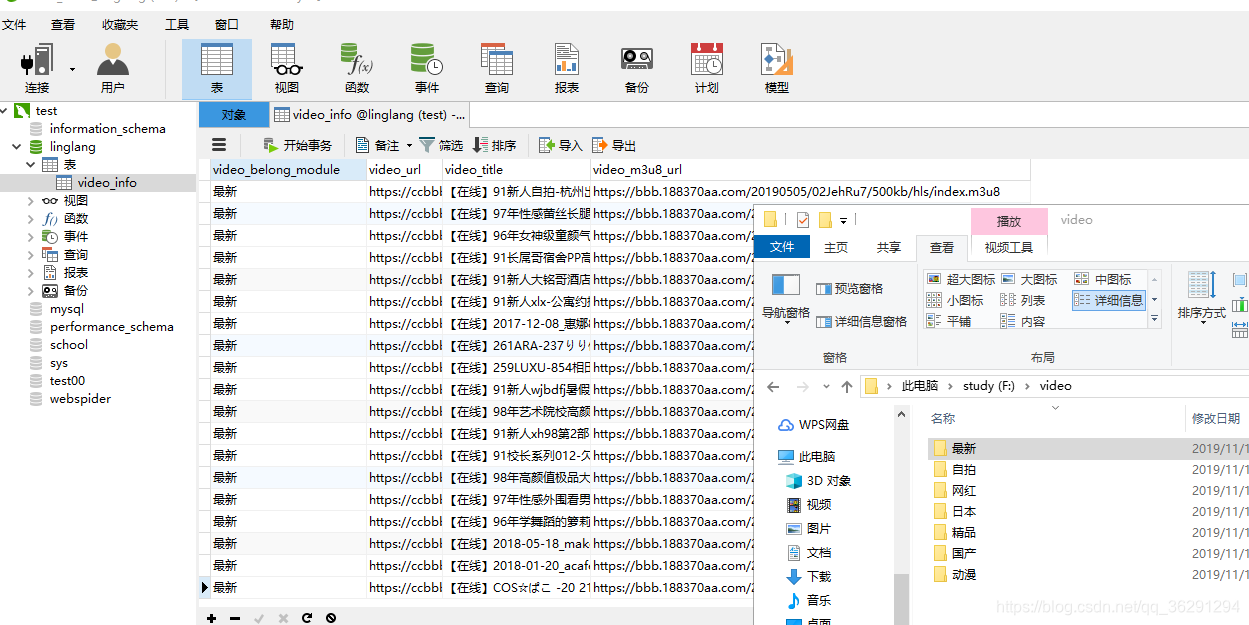
定义具体模块页面的解析函数,支持分页爬取:


返回item给管道文件:

实现一个去重管道:

再实现将数据存入mysql的存储管道,此处也可选择其他种类数据库进行存储:

其实呢,到这已经能够进行爬取了。但是我们利用scrapy对该网站频繁发起这么多次请求,对方服务器判定我们为爬虫时,会强行关闭与我们之间的连接。
虽然scrapy会将这些没有爬取成功的请求重新放回调度器,等待之后连接成功再发送请求,但是这样会浪费我们一些时间。
为了提高效率,当本地请求失败后,我们可以在下载中间件中使用动态代理重新发起请求:

最后启动爬虫,等待爬虫结束,查看数据库,满满的收获~






- 荣耀申请灵动胶囊/精灵商标:领先苹果iPhone 14 Pro四年
- 怎么查宽带上网时间 具体方法如下
- 甲骨文公司官宣:将在OCI中部署上万个英伟达顶级计算GPU
- dnf深渊怎么开 关于dnf深渊怎么开的问题
- 华硕主板前面板耳机没有声音的解决方法-环球今热点
- KOOBEE A106怎么样
- Meta最强交易官离开公司 曾帮助脸书收购Ins
- WindowsTerminal现已成为微软最新系统默认体验终端工具
- win8运行在哪里 如何打开win8系统的运行命令-全球快消息
- 网页视频看不了怎么办_网页视频看不了的解决方法-每日报道
- win7玩cf老是与主机连接不稳定的解决方法-报资讯
- 无线AP是什么 无线AP怎么用
- 康福中国 Camfrog 6.0 中文版安装教程(英文版转中文版设置方法)
- LED背光板原理是什么 LED背光板原理详细介绍
- windows双系统怎么设置启动顺序 win双系统默认开机启动项设置方法-环球即时
- 安装电地暖价格是多少 安装电地暖价格预算
- 广汽透露将在明年投产自主品牌PHEV产品 并分析相关车型布局
- win7系统安装英雄联盟补丁包的两种方法-热消息
- qq腾讯网迷你版怎么设置不弹岀来
- 联想win8重装系统步骤 联想win8系统重装教程-世界速看
- 世纪之星机箱怎么样 世纪之星机箱介绍
- ibackupbot怎么用 ibackupbot使用教程(附ibackupbot中文版下载地址)
- 原版dell oem xp pro sp3光盘镜像下载地址-环球资讯
- win10系统电脑没有手机驱动的解决方法-时快讯
- 163邮箱登录入口 手机端163邮箱登录入口
- 蔚来总裁秦力洪回复网友建议 并称将考虑开卖欧版汽车一事
- QQ空间日志图片如何加水印
- 了解什么是电源控制器 电源控制器功能
- IPhone13pro电池容量多大-IPhone13Pro电池参数续航介绍
- 哪种植物会寄生在梭梭根部?蚂蚁庄园今日答案11.23
- 华为nova5pro和nova5i的区别
- 如何在手机QQ中下载表情包 具体操作方法
- 怎么自动识别查询快递单号查询-自动识别查询快递单号查询方法
- 电脑打电话给手机步骤详解
- win7系统下怎么调cf烟雾头-环球热议
- 电视直播软件哪个好 网络电视直播软件排行2014详情介绍
- MSN帐号格式以及MSN用户名格式的详细介绍
- 电脑进入桌面后黑屏如何修复_电脑经常进入桌面之后黑屏的处理方法-全球新动态
- xbox360手柄模拟器怎么样 xbox360手柄模拟器介绍
- ie浏览器打不开_ie浏览器打不开网页_IE浏览器打不开网页的解决方法
- 把rmvb格式转换成dvd的详细图文教程
- 数码闲聊站曝光OPPO新折叠屏手机:电池容量有望超过ZFlip4
- Win7锁定计算机快捷键是什么 Win7使用锁定计算机快捷键的方法-全球动态
- xr是什么意思-xr改的意思介绍
- 如何让win7自动拨号上网|让win7自动拨号上网的教程-全球速看
- 电脑性能怎么检测 电脑性能检测的方法
- Win7系统打开IE浏览器后页面自动关闭的四种解决方法-重点聚焦
- Win10系统如何打开内涵图种子-世界微速讯
- 鸿海董事长刘扬伟:新款电车零配件将优先采用MIH联盟成员产品
- ie浏览器网页字体怎么变大|如何将网页字体变大-全球速讯
- windows xp3 原版下载_windows xp3 原版下载地址-环球热资讯
- 怎么用硬盘装xp系统 硬盘安装xp系统步骤图解-全球聚焦
- 如何禁用和开启电脑光驱 电脑禁用和开启光驱的方法-世界新要闻
- 分析师称苹果将在后年发布OLED版iPadPro 屏幕亮度获提升
- deepmoss 2022 Autumn Winter 甲板之上
- “抱冷门”赢世界杯定制礼品!容声WILL健康冰箱羊毛“鲜”薅为敬
- “狲思邈”离世,中国“最穷”动物园出圈
- 1.8万就能拥有布加迪!全球第一款全碳纤维智能手表发布-微资讯
- 精悍小巧,功能不少! 华硕电竞路由新品RT-AX57来了
- P站宣布将区分AI画图和真人作品 提供单独的排行榜-环球速读
- 迷宫探险动作游戏《迷宫传说》繁体中文版今天正式上市!-当前快播
- “极境之域”加载中,请准备进入
- 荣耀畅玩40 Plus新机发布:首发1199元 6000mAh大电池
- PS4版《女神异闻录5:皇家版》价格永久下调100元 10月31日生效-世界球精选
- 值得买科技获2022年度第一批“北京市企业技术中心”认定
- 有了这个智能枕头 睡觉再也不打鼾了!-环球精选
- 淘宝购物车扩容至300 新增分组、优惠筛选等功能
- 摸鱼5分钟:去鹤岗全款买房幸福感飙升 90后父母给儿子取名叫“张总”-播报
- 秋冬大衣千万别在款式上作妖了!
- 联想专业电竞鼠标来了:拯救者M7将于10月底发布-环球时讯
- 最酷的姐姐就是穿着球鞋把婚结了
- 腾讯阿里抢在双11前一连三通
- 京东PLUS会员年卡76元-全球滚动
- 今晚八点正式开启预售 京东11·11促销时间表曝光
- 【手慢无】摆着都美 华硕创意游戏电脑主机只需6199元-新视野
- iPhone 14 Plus减产规模在70%-90% 刷新苹果历史
- 《寂静岭2重制版》PS5版无加载画面 支持触觉反馈等-快资讯
- 联想小新Air14 2023公开部分规格:新笔电将搭载下沉式键盘
- 骁龙处理器排名天梯图最新 骁龙处理器排行榜2022-每日聚焦
- 北京冬奥上火爆全球:谷爱凌获最佳女运动员表现奖
- 缺锂怎么办?马斯克式解决方案:特斯拉自己干
- HKC新MiniLED显示器上架:2K 240Hz 首发价2999元-全球报道
- 科乐美推出《寂静岭》周边:护士姐姐依旧吸睛-全球头条
- 超越人类的交互感受,深度体验小鹏G9智能语音-全球播报
- 朗科新推绝影NV5000-t固态硬盘 温控技术更高 售价暂未公布
- 4999元起,机械革命极光Z游戏本发布,最高可选i7-12700H-观察
- 【手慢无】无蓝光液晶屏 小米液晶小黑板仅售89元-当前动态
- Redmi X Pro 正式发布-天天快报
- ios16.1正式版推送时间计划 ios16.1正式版什么时候更新-热头条
- 【手慢无】锐龙R7-5800H处理器+2.8K OLED屏 华硕无畏14电脑入手仅需3999元-天天快播
- 微信朋友圈提到了我是什么意思 提醒谁看别人能看到吗-当前视点
- 【手慢无】小巧精悍的惠普迷你主机秒杀价2997元-世界速看料
- DXO披露Xperia10IV影像测试分数 并称其具备户外拍摄细节
- 【手慢无】联想ThinkPad neo 14英寸高性能标压笔记本,活动直降1000元-每日看点
- 特斯拉真正自动驾驶要来了?马斯克将在2023年申请监管批准
- Nreal携手LGD推出开「大」联名礼盒 LGD夺冠0元到手
- 【手慢无】护眼学习平板联想小新Pad只要899元。-天天新动态
- 联想概念新品亮相LenovoTechWorld 并提出CyberSpaces方案
- 【手慢无】小尺寸游戏平板,联想拯救者y700活动优惠价只要2269元-环球热消息
- 双·11大促即将开启 三款主流价位段3060游戏本闭眼入-天天热资讯
新闻排行
- 合创A06新车已通过工信部申报 车长大于Model3定位中型电轿
- 理想汽车又一SUV新车型曝光 定位不超过L9或为理想ONE升级款
- 曝英特尔已改动Xe-HPG ScavengerHunt奖池设置 备选有所增加
- 本田讴歌上线首款纯电SUV预告视频 将电气化外观设计完全展现
- iPhone14Pro顶栏多种自定义显示设置曝光 选择丰富可占满一行
- 4K全色投影新品ViddaC1惊艳亮相 超高清音画品质极其震撼
- 理想L9将在明日正式下线 新车将仅包含Max版配置 定价已公开
- 微星多款X670主板已提前上架 最高定价超六百欧元令人咋舌
- POCO M4 5G国际版新机全球亮相 4+64GB版本可售219欧元
- GalaxyS22幽紫秘境版现身官方商城 玻璃背板具哑光感品质出众
精彩推荐
超前放送
- 《哥谭骑士》主机版21日0点正式...
- 【手慢无】惠普2022款锐14 锐龙...
- 微软文件透露:PS独占《漫威金刚...
- Redmi Note 12订购福利公布 ...
- 雷鸟创新发布新品XR眼镜,MicroO...
- 《大富翁11》今日上线游戏攻略3...
- 洞察绿色办公打印市场 格之格聚...
- 小米正式宣布 Redmi Note12普及两亿像素
- 【手慢无】双屏同显异显均支持 ...
- 新时代,新征程 | 利亚德助力...
- 什么才叫成功?雷军称小米成电车...
- 72岁被吹“逆天童颜脸”的王薇薇...
- 海信智慧生活馆日销40余万元,场...
- 晚8点开始 掠夺者圣盾7000台式...
- 苹果 iPadOS 16 正式版官宣 ...
- 带给玩家顶级体验 罗技推出顶级...
- 全球首款Gallery 3彩色墨水屏智...
- 雷军称小米汽车要跻身世界前五 ...
- 中国移动:5G套餐客户数累计达5....
- 罗永浩真是命好,总有人救!
- 樱桃的最新机械键盘轴Ergo Clea...
- 有气质的漂亮姐姐都穿费尔岛毛衣
- 曝iPhone SE 4将采用6.1英寸LC...
- 双十一前淘宝购物车扩容至300:...
- 索尼Xperia 5 IV国行开售:骁...
- 传PS5 Pro开发组件已经分发至各...
- 诺基亚发布2022年Q3财报 第三季...
- 东方甄选开通多个淘宝直播账号 ...
- 德意煤气灶怎么样 德意煤气灶特...
- 诺基亚c503怎么样 诺基亚c503参数配置
- 尼康d300s说明书介绍【尼康D300s相机】
- qq空间怎么免费装扮 qq空间免费...
- 马斯克卖香水、小鹏卖麻将,大厂...
- 带给玩家顶级体验 罗技推出顶级...
- 联想z465怎么样 联想Z465A-NNI报价多少
- 电竞党双·11剁手指南:拯救者Y9...
- 调查:67%的欧洲科技界女性认为...
- iPhone7 Plus多少钱?iPhone7 Plus价格
- 荣畅玩40 Plus价格1199元 搭载...
- 高清网络电视机顶盒什么牌子好 ...
- root权限有什么用 获取root权限的作用
- Ti10冠军雪碧卫冕失败爆冷出局 ...
- 销服一体化改造升级 联想告诉你...
- lol德玛西亚皇子常用技巧分析
- 手机内存满了怎么清理?大家知道吗
- webcheck.dll是什么
- 马斯克发推特宣布BurntHair香水...
- 三星s4和苹果5哪个好 三星S4...
- 平板电脑怎么连接网络 平板连接...
- 索尼t77数码相机报价与测评 索...

